Model based Subsampling for One million songs Data
Source:vignettes/MB_Poisson_Reg_One_Million_Songs.Rmd
MB_Poisson_Reg_One_Million_Songs.Rmd
# Load the R packages
library(NeEDS4BigData)## Error in get(paste0(generic, ".", class), envir = get_method_env()) :
## object 'type_sum.accel' not found
library(ggplot2)
library(ggpubr)
library(kableExtra)
library(tidyr)
library(psych)
library(gam)
# Theme for plots
Theme_special<-function(){
theme(legend.key.width= unit(1,"cm"),
axis.text.x= element_text(color= "black", size= 12, angle= 30, hjust=0.75),
axis.text.y= element_text(color= "black", size= 12),
strip.text= element_text(colour= "black", size= 12, face= "bold"),
panel.grid.minor.x= element_blank(),
axis.title= element_text(color= "black", face= "bold", size= 12),
legend.text= element_text(color= "black", size= 11),
legend.position= "bottom",
legend.margin= margin(0,0,0,0),
legend.box.margin= margin(-1,-2,-1,-2))
}Understanding the One million songs data
Echo nest collected data to understand songs and their popularity using their play counts over 1 million users based on the songs basic information, such as duration, tempo, loudness, etc. This data was transformed accordingly as in the works Bertin-Mahieux et al. (2011) to study the number of counts through the songs features. This data contains \(6\) columns and has \(205,032\) observations, first column is the response variable and the rest are covariates. We consider the covariates a) duration (\(x_1\)), b) loudness (\(x_2\)), c) tempo (\(x_3\)), d) artist hotness (\(x_4\)), and e) song hotness (\(x_5\)) to model the response, the number of play counts for each song. The covariates \(x_1,x_2,x_3\) are scaled to be mean of zero and variance of one, while the remaining covariates are in between \(0-1\). For the given data subsampling methods are implemented assuming the main effects model can describe the data.
# Selecting 100% of the big data and prepare it
Original_Data<-One_million_songs
colnames(Original_Data)<-c("Y",paste0("X",1:ncol(Original_Data[,-1])))
# Scaling the covariate data
for (j in 2:4) {
Original_Data[,j]<-scale(Original_Data[,j])
}
head(One_million_songs) %>%
kable(format = "html",
caption = "First few observations of the one million songs data.")| Counts | Duration | Loudness | Tempo | Artist_Hotness | Song_Hotness |
|---|---|---|---|---|---|
| 2 | 200.6199 | -16.492 | 102.556 | 0.3953858 | 0.4395641 |
| 2 | 133.0934 | -17.953 | 137.562 | 0.3923937 | 0.0000000 |
| 4 | 243.5391 | -6.749 | 108.212 | 0.4347369 | 0.5654475 |
| 2 | 190.8763 | -17.787 | 122.996 | 0.4894737 | 0.5076695 |
| 1 | 210.2069 | -9.951 | 123.655 | 0.3529046 | 0.5317221 |
| 2 | 281.4951 | -12.496 | 100.285 | 0.4855715 | 0.6275047 |
# Setting the sample sizes
N<-nrow(Original_Data); M<-250; k<-seq(8,20,by=2)*100; rep_k<-rep(k,each=M)Based on this model the methods random sampling, leverage sampling (Ma, Mahoney, and Yu 2014; Ma and Sun 2015), \(A\)- and \(L\)-optimality subsampling (Ai et al. 2021; Yao and Wang 2021) and \(A\)-optimality subsampling with response constraint (Zhang, Ning, and Ruppert 2021) are implemented on the big data.
# define colors, shapes, line types for the methods
Method_Names<-c("A-Optimality","L-Optimality","A-Optimality MC",
"Shrinkage Leverage","Basic Leverage","Unweighted Leverage",
"Random Sampling")
Method_Colour<-c("#BBFFBB","#50FF50","#00BB00",
"#F76D5E","#D82632","#A50021","#000000")
Method_Shape_Types<-c(rep(17,3),rep(4,3),16)The obtained samples and their respective model parameter estimates are over \(M=250\) simulations across different sample sizes \(k=r_f=(800,\ldots,2000)\). We set the initial sample size of \(r_0=400\) for the methods that requires a random sample. From the final samples, model parameters of the assume model are estimated. These estimated model parameters are compared with the estimated model parameters of the full big data through the mean squared error \(MSE(\tilde{\beta}_k,\hat{\beta})=\frac{1}{MJ}\sum_{i=1}^M \sum_{j=1}^J(\tilde{\beta}_{k,j} - \hat{\beta}_j)^2\). Here, \(\tilde{\beta}_k\) is the estimated model parameters from the sample of size \(k\) and \(\hat{\beta}\) is the estimated model parameters from the full big data, while \(j\) is index of the model parameter.
Random sampling
Below is the code for this implementation.
# Random sampling
Final_Beta_RS<-matrix(nrow = length(k)*M,ncol = ncol(Original_Data[,-1])+1)
for (i in 1:length(rep_k)) {
Temp_Data<-Original_Data[sample(1:N,rep_k[i]),]
glm(Y~.-1,data=Temp_Data,family="poisson")->Results
Final_Beta_RS[i,]<-c(rep_k[i],coefficients(Results))
if(i==length(rep_k)){print("All simulations completed for random sampling")}
}## [1] "All simulations completed for random sampling"
Final_Beta_RS<-cbind.data.frame("Random Sampling",Final_Beta_RS)
colnames(Final_Beta_RS)<-c("Method","Sample",paste0("Beta",1:5))Leverage sampling
# Leverage sampling
## we set the shrinkage value of S_alpha=0.9
NeEDS4BigData::LeverageSampling(rf=rep_k,Y=as.matrix(Original_Data[,1]),
X=as.matrix(Original_Data[,-1]),N=N,
S_alpha = 0.9,family = "poisson")->Results## Basic and shrinkage leverage probabilities calculated.## Sampling completed.A- and L-optimality subsampling
# A- and L-optimality subsampling for GLM
NeEDS4BigData::ALoptimalGLMSub(r0=400,rf=rep_k,
Y=as.matrix(Original_Data[,1]),
X=as.matrix(Original_Data[,-1]),
N=N,family = "poisson")->Results## Step 1 of the algorithm completed.## Step 2 of the algorithm completed.A-optimality subsampling with measurement constraints
# A-optimality subsampling without response
NeEDS4BigData::AoptimalMCGLMSub(r0=400,rf=rep_k,
Y=as.matrix(Original_Data[,1]),
X=as.matrix(Original_Data[,-1]),
N=N,family="poisson")->Results## Step 1 of the algorithm completed.## Step 2 of the algorithm completed.Summary
# Summarising Results of Scenario one
Final_Beta<-rbind(Final_Beta_RS,Final_Beta_LS,
Final_Beta_ALoptGLM,Final_Beta_AoptMCGLM)
# Obtaining the model parameter estimates for the full big data model
glm(Y~.-1,data = Original_Data,family="poisson")->All_Results
coefficients(All_Results)->All_Beta
matrix(rep(All_Beta,by=nrow(Final_Beta)),nrow = nrow(Final_Beta),
ncol = ncol(Final_Beta[,-c(1,2)]),byrow = TRUE)->All_Beta
remove(Final_Beta_RS,Final_Beta_LS,Final_Beta_ALoptGLM,
Final_Beta_AoptMCGLM,Temp_Data,Results,All_Results)The mean squared error is plotted below.
# Obtain the mean squared error for the model parameter estimates
MSE_Beta<-data.frame("Method"=Final_Beta$Method,
"Sample"=Final_Beta$Sample,
"SE"=rowSums((All_Beta - Final_Beta[,-c(1,2)])^2))
MSE_Beta$Method<-factor(MSE_Beta$Method,levels = Method_Names,labels = Method_Names)
Mean_Data <- MSE_Beta |>
group_by(Method,Sample) |>
dplyr::summarise(Mean = mean(SE),
min=quantile(SE,0.05),
max=quantile(SE,0.95), .groups = "drop")
# Plot for the mean squared error with all methods
ggplot(data=Mean_Data,aes(x=factor(Sample),y=Mean,color=Method,shape=Method))+
xlab("Sample Size")+ylab("Squared Error")+
geom_point(size=3,position = position_dodge(width = 0.5))+
geom_line(data=Mean_Data,aes(x=factor(Sample),y=Mean,group=Method,color=Method),
position = position_dodge(width = 0.5))+
geom_errorbar(data=Mean_Data,aes(ymin=min,ymax=max),
width=0.3,position = position_dodge(width = 0.5))+
scale_color_manual(values = Method_Colour)+
scale_shape_manual(values = Method_Shape_Types)+
theme_bw()+Theme_special()+
guides(colour = guide_legend(nrow = 3))->p1
# Plot for the mean squared error with all methods except unweighted leverage
ggplot(data=Mean_Data[Mean_Data$Method != "Unweighted Leverage",],
aes(x=factor(Sample),y=Mean,color=Method,shape=Method))+
xlab("Sample Size")+ylab("Squared Error")+
geom_point(size=3,position = position_dodge(width = 0.5))+
geom_line(data=Mean_Data[Mean_Data$Method != "Unweighted Leverage",],
aes(x=factor(Sample),y=Mean,group=Method,color=Method),
position = position_dodge(width = 0.5))+
geom_errorbar(data=Mean_Data[Mean_Data$Method != "Unweighted Leverage",],
aes(ymin=min,ymax=max),width=0.3,
position = position_dodge(width = 0.5))+
scale_color_manual(values = Method_Colour[-6])+
scale_shape_manual(values = Method_Shape_Types[-6])+
theme_bw()+Theme_special()+
guides(colour = guide_legend(nrow = 3))->p2
ggarrange(p1,p2,nrow = 2,ncol = 1,labels = "auto")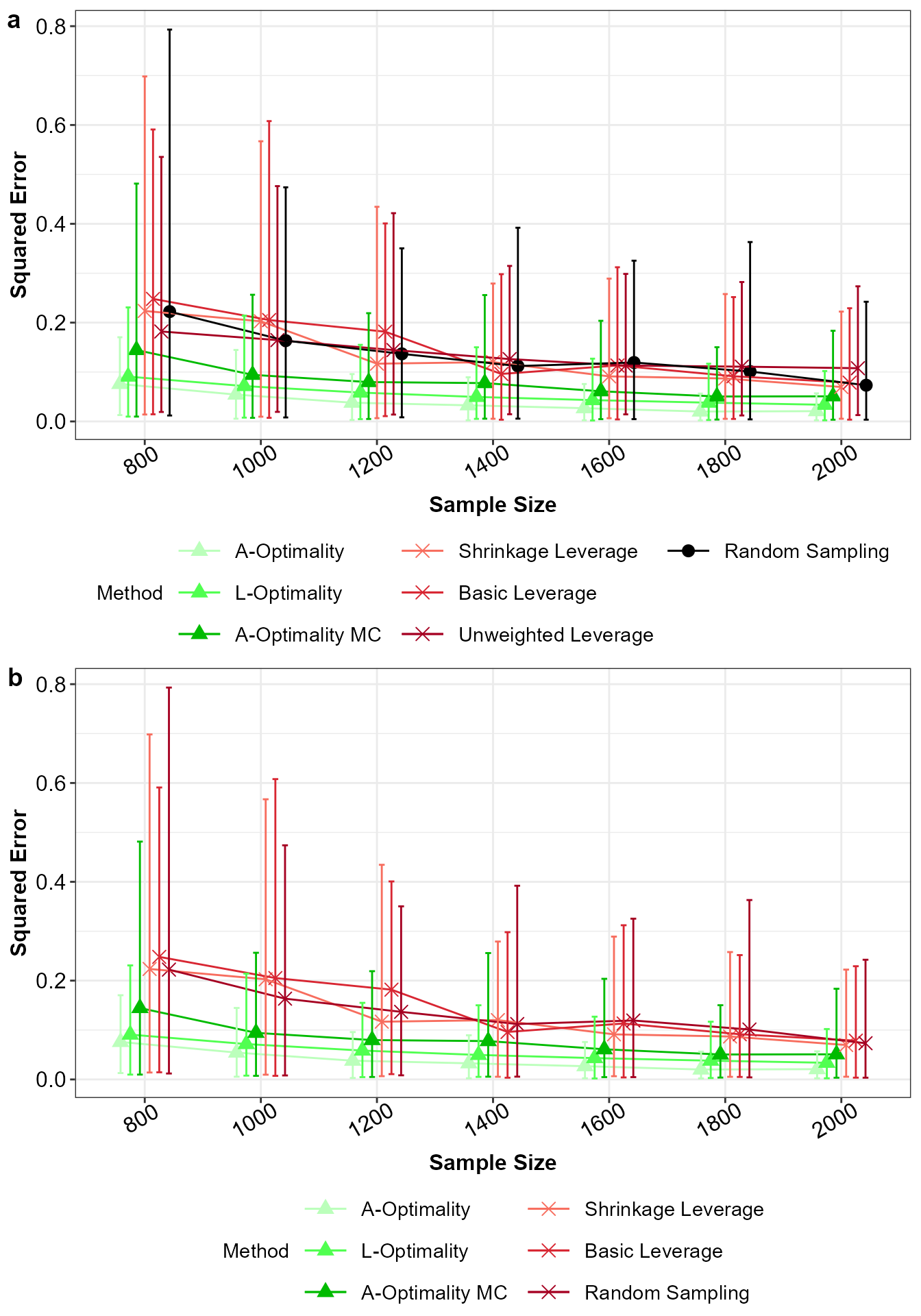
Mean squared error for a) all the subsampling methods and b) without unweighted leverage sampling, with 5% and 95% percentile intervals.