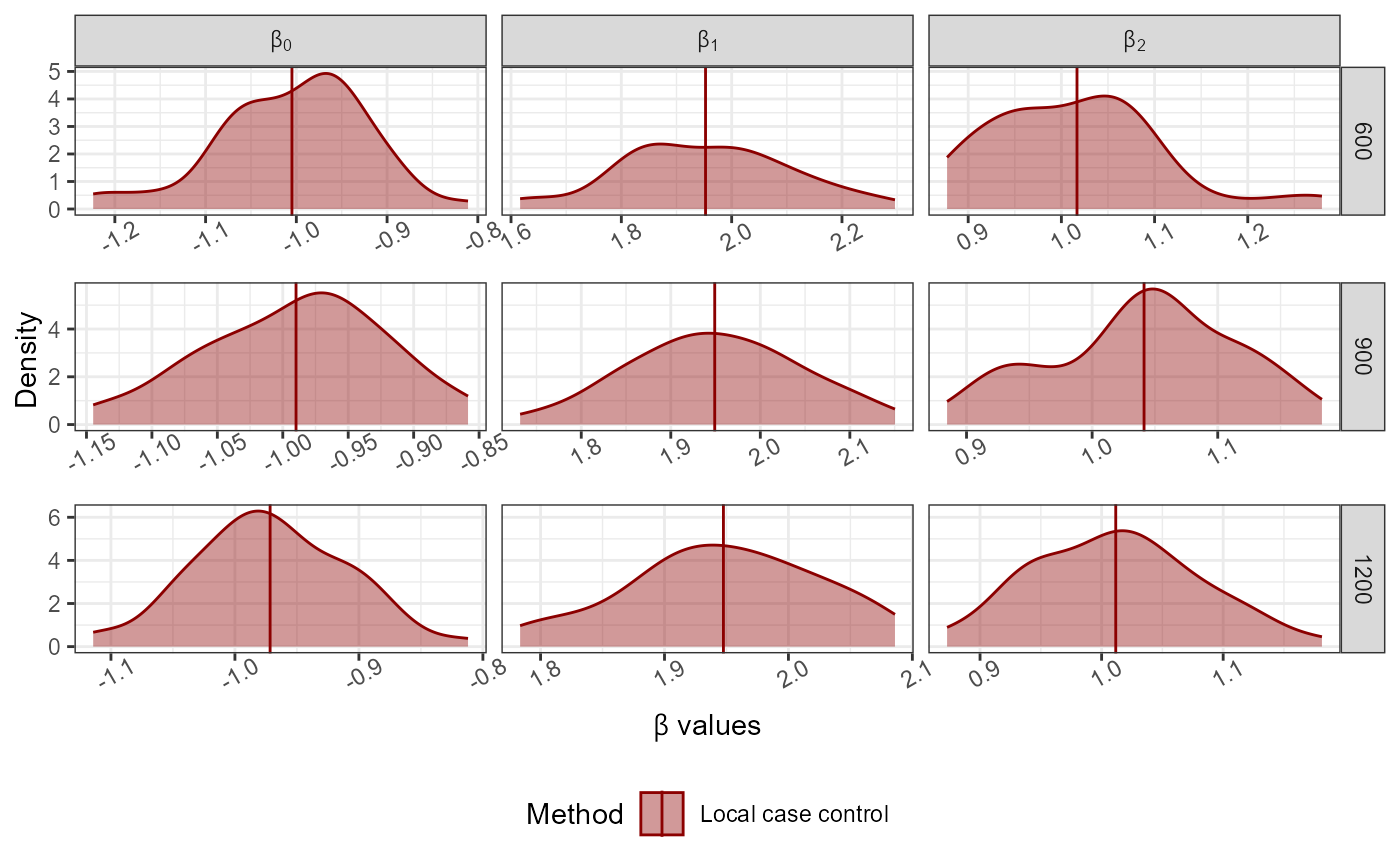
Using this function sample from big data under logistic regression to describe the data. Sampling probabilities are obtained based on local case control method.
Arguments
- r0
sample size for initial random sample
- rf
final sample size including initial(r0) and case control(r) samples
- Y
response data or Y
- X
covariate data or X matrix that has all the covariates (first column is for the intercept)
- N
size of the big data
Value
The output of LCCsampling gives a list of
Beta_Estimates estimated model parameters in a data.frame after sampling
Sample_LCC_Sampling list of indexes for the initial and optimal samples obtained based on local case control sampling
Sampling_Probability vector of calculated sampling probabilities for local case control sampling
Details
Two stage sampling algorithm for big data under logistic regression.
First obtain a random sample of size \(r_0\) and estimate the model parameters. Using the estimated parameters sampling probabilities are evaluated for local case control.
Through the estimated sampling probabilities an optimal sample of size \(r \ge r_0\) is obtained. Finally, the optimal sample is used and the model parameters are estimated.
NOTE : If input parameters are not in given domain conditions necessary error messages will be provided to go further.
If \(r \ge r_0\) is not satisfied then an error message will be produced.
If the big data \(X,Y\) has any missing values then an error message will be produced.
The big data size \(N\) is compared with the sizes of \(X,Y\) and if they are not aligned an error message will be produced.
References
Fithian W, Hastie T (2015). “Local case-control sampling: Efficient subsampling in imbalanced data sets.” Quality control and applied statistics, 60(3), 187--190.
Examples
Dist<-"Normal"; Dist_Par<-list(Mean=0,Variance=1)
No_Of_Var<-2; Beta<-c(-1,2,1); N<-10000; Family<-"logistic"
Full_Data<-GenGLMdata(Dist,Dist_Par,No_Of_Var,Beta,N,Family)
r0<-300; rf<-rep(100*c(6,9,12),50); Original_Data<-Full_Data$Complete_Data;
LCCsampling(r0 = r0, rf = rf, Y = as.matrix(Original_Data[,1]),
X = as.matrix(Original_Data[,-1]),
N = nrow(Original_Data))->Results
#> Step 1 of the algorithm completed.
#> Step 2 of the algorithm completed.
plot_Beta(Results)
#> Picking joint bandwidth of 0.0311
#> Picking joint bandwidth of 0.0392
#> Picking joint bandwidth of 0.0311